Suicide Rate Report (1985 to 2016)
1. Introduction
Due to a high competion in every field nowadays. We cannot deny that we must speed our pace to get ahed of others. What does it lead to? It leads to anxiety, depression, and endless tiring situations. As a consequence, suicide rates sky rocket daily and they seem to not soon decrease.
2. Objectives
The main objectives of this short report are to raise the awareness of suicide rates, and provide insightful information for future research and usage.
3. Data Analysis
Import all necessary libraries
# Import Data Manipluation Libraries
import pandas as pd
import numpy as np
# Import Data Visualization
import matplotlib.pyplot as plt
import seaborn as sns
from bokeh.core.properties import value
from bokeh.io import show, save, output_notebook, export_png, export_svgs
from bokeh.layouts import column, gridplot
from bokeh.plotting import figure, output_file
from bokeh.models.glyphs import HBar
from bokeh.models import ColumnDataSource, Legend, HoverTool, layouts, CustomJS, Select, Circle, RangeTool
from bokeh.models import Toggle, BoxAnnotation, Div, Row
from bokeh.models import LinearColorMapper, ColorBar, BasicTicker, PrintfTickFormatter
from bokeh.palettes import all_palettes
from bokeh.transform import cumsum, jitter, transform
from bokeh.embed import file_html, components
import plotly
plotly.tools.set_credentials_file(username='', api_key='')
import plotly.plotly as py
import plotly.graph_objs as go
import plotly.figure_factory as ff
from plotly.offline import download_plotlyjs, init_notebook_mode, plot, iplot
init_notebook_mode(connected=True)
The table below shows an example of the dataset which contains several factors that will be analysed
df = pd.read_csv('https://raw.githubusercontent.com/nat236919/Data_Science/master/Project_1_Suicide_Rate/master.csv')
display(df.head(5))

Countries
By analysing the dataset based on countries and ‘suicides/100k pop’, the author depicts the results as a world map below.
However, due to missing values from some countires, the world map is not fully complete.

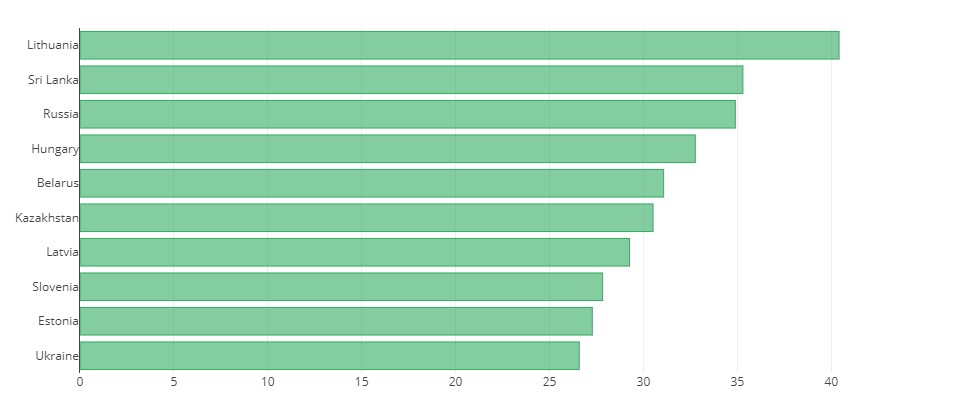
Interesingly, based on the data collected from 1985 to 2016. Lithuania had the highest suicide rates per 100k people. Followed by Sri Lanka and Russia respectively. The chart below shows the top 10 highest suicide rates.
df_grouped_country = df_grouped_country.sort_values(by=['suicides/100k pop'], ascending=False)
df_grouped_country.head(10)
x = df_grouped_country['suicides/100k pop'][:10].tolist()[::-1]
y = df_grouped_country['country_label'][:10].tolist()[::-1]
data = [go.Bar(
x=x,
y=y,
marker=dict(
color='rgba(50, 171, 96, 0.6)',
line=dict(
color='rgba(50, 171, 96, 1.0)',
width=1),
),
orientation = 'h',
)]
py.iplot(data, filename='horizontal-bar')
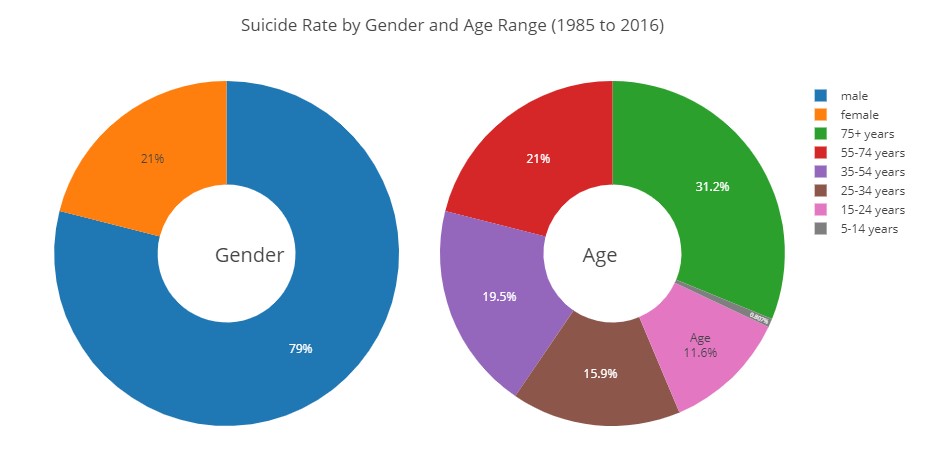
Gender and Age
By exploring regarding sex and age range, it was found that 79% of the participants were males, and 21% were females. And most of them were aged more than 75 years old.
df_grouped_sex_sr = df.groupby(['sex'])['suicides/100k pop'].mean().reset_index()
df_grouped_age_sr = df.groupby(['age'])['suicides/100k pop'].mean().reset_index()
df_grouped_sex_sr.head()
df_grouped_age_sr.head()
colors = ['#FEBFB3', '#E1396C', '#96D38C', '#D0F9B1']
# Plot Donut Charts
fig = {
"data": [
{
"values": df_grouped_sex_sr['suicides/100k pop'].tolist(),
"labels": df_grouped_sex_sr['sex'].tolist(),
"domain": {"column": 0},
"name": "Sex",
"hoverinfo":"label+percent+name",
"hole": .4,
"type": "pie"
},
{
"values": df_grouped_age_sr['suicides/100k pop'].tolist(),
"labels": df_grouped_age_sr['age'].tolist(),
"text":['Age'],
"textposition":"inside",
"domain": {"column": 1},
"name": "Age Range",
"hoverinfo":"label+percent+name",
"hole": .4,
"type": "pie"
}],
"layout": {
"title":"Suicide Rate by Gender and Age Range (1985 to 2016)",
"grid": {"rows": 1, "columns": 2},
"annotations": [
{
"font": {
"size": 20
},
"showarrow": False,
"text": "Gender",
"x": 0.215,
"y": 0.5
},
{
"font": {
"size": 20
},
"showarrow": False,
"text": "Age",
"x": 0.775,
"y": 0.5
}
]
}
}
py.iplot(fig, filename='donut')
Suicide Rates on Gender and Age
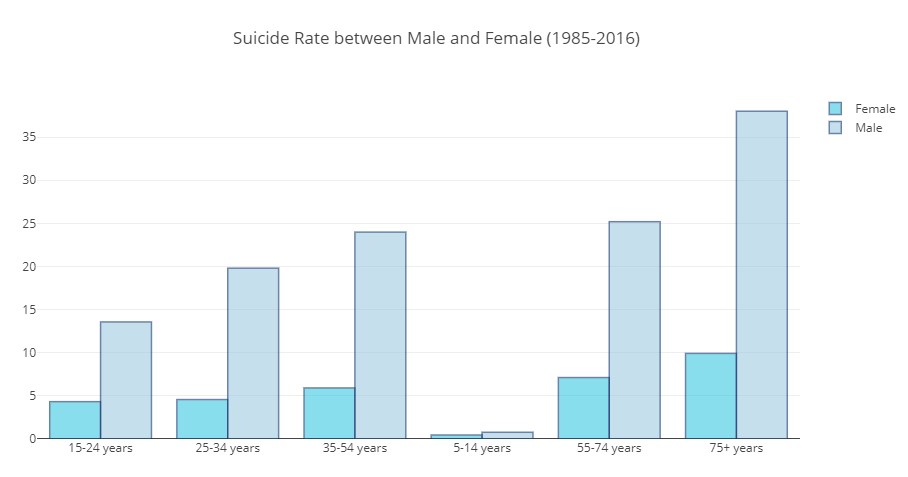
According to the results, it can be said that Males had higher suicide rates compared to females in every age range. It is noticable that those who aged more than 75 years old had the highest suicide rates compared to the others.
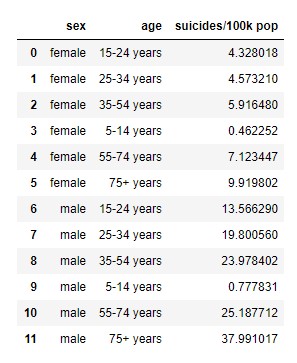
df_grouped_sex_age = df.groupby(['sex', 'age'])['suicides/100k pop'].mean().reset_index()
display(df_grouped_sex_age)
x_label = list(df_grouped_sex_age['age'])[:6]
y_female = df_grouped_sex_age['suicides/100k pop'][:6].tolist()
y_male = df_grouped_sex_age['suicides/100k pop'][6:].tolist()
trace1 = go.Bar(
x= x_label,
y=y_female,
name='Female',
marker=dict(
color='rgb(58,200,225)',
line=dict(
color='rgb(8,48,107)',
width=1.5),
),
opacity=0.6
)
trace2 = go.Bar(
x= x_label,
y=y_male,
name='Male',
marker=dict(
color='rgb(158,202,225)',
line=dict(
color='rgb(8,48,107)',
width=1.5),
),
opacity=0.6
)
data = [trace1, trace2]
layout = go.Layout(
barmode='group',
title='Suicide Rate between Male and Female (1985-2016)'
)
fig = go.Figure(data=data, layout=layout)
py.iplot(fig, filename='grouped-bar')
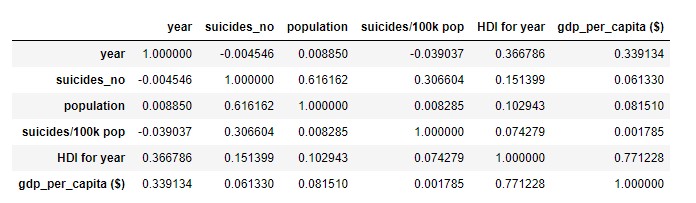
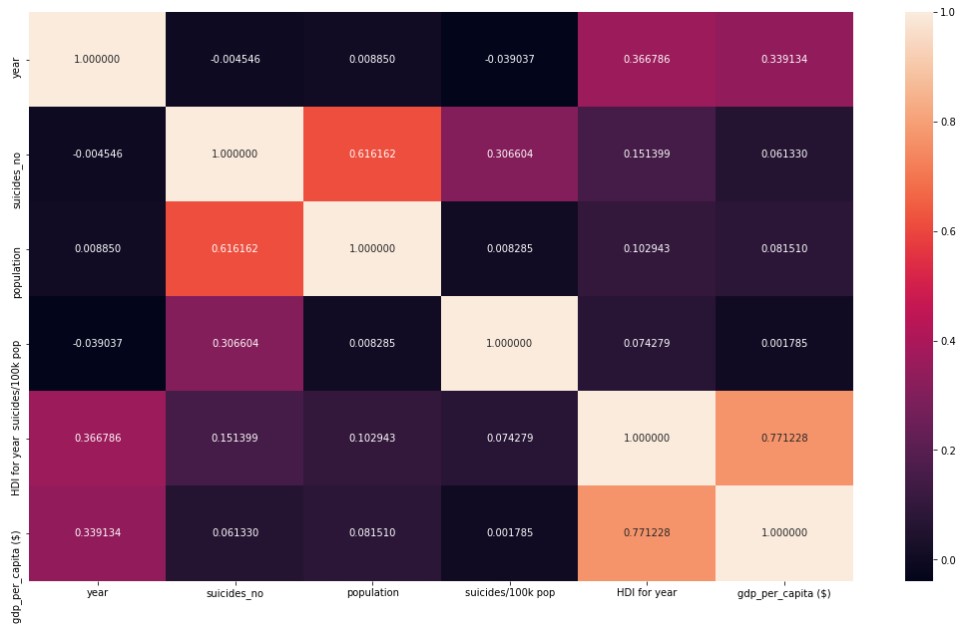
Correlations among Factors
By revealing correlations among factors provided by the dataset. It was found that the information was not enough for discovering the main factor of an increasing suicide rates.
sub_df = df[:] #Subsetting the data
cor = sub_df.corr() #''Calculate the correlation of the above variables
display(cor)
# Display Heatmap
fig, ax = plt.subplots()
fig.set_size_inches(18.5, 10.5)
sns.heatmap(cor, annot=True, square=False, fmt='f') # Plot the correlation as heat map